浅谈正则表达式
这个东西很多程序员在开发中,会用到。我当时学习这个主要是看一些源码的时候思考如何绕过。。
简单操作
字符组([])允许匹配一组可能出现的字符。
使用字符组匹配Java和 java
[Jj]ava
请你使用字符组匹配Ruby、Rube、ruby、rube
[Rr]ub[ey]
区间
正则表达式引擎在字符组中使用连字符(-)代表区间
- 要匹配任意数字可以使用
[0-9]; - 如果想要匹配所有小写字母,可以写成
[a-z]; - 想要匹配所有大写字母可以写成
[A-Z]
匹配数据所有的数字、小写字母和大写字母
[0-9a-zA-Z]
匹配特殊字符
正则表达使用了 - 号代表了区间,但是我们有时候需要匹配的符号就是 -号,该怎么办呢?
这个时候我们需要对-号进行转义操作,即 \-
请你编写正则表达式匹配下列符号。

\W
取反
可以通过在字符数组开头使用 ^ 字符实现取反操作,从而可以反转一个字符组(意味着会匹配任何指定字符之外的所有字符)。

这里的 n[^e] 的意思就是n后面的字母不能为 e。
快捷键
\w
与任意单词字符匹配,任意单词字符表示 [A-Z]、 [a-z]、[0-9]、_
\d
与任意数字匹配
\s
\s快捷方式可以匹配空白字符,比如空格,tab、换行等。

\b
\b 匹配的是单词的边界,例如
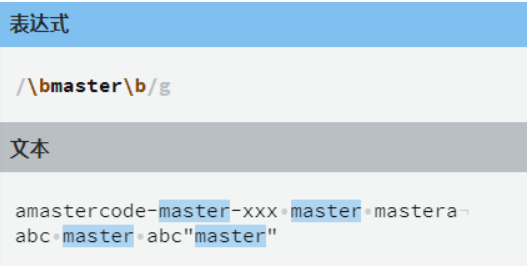
\bmaster\b 就仅匹配有边界的master单词
快捷方式取反
快捷方式也可以取反,例如对于\w的取反为\W,将小写改写成大写即可,

开始和结束
正则表达式中 ^指定的是一个字符串的开始,$指定的是一个字符串的结束。
请编写正则表达式匹配以OS结尾的字符串。
OS$
任意字符
.字符代表匹配任何单个字符,它只能出现在方括号以外。
值得注意的是: .字符只有一个不能匹配的字符,也就是换行符(\n)
匹配任意字母之后是ar的字符串。
.ar
可选字符
有时,我们可能想要匹配一个单词的不同写法,比如color和colour,或者honor与honour。
这个时候我们可以使用 ? 符号指定一个字符、字符组或其他基本单元可选,这意味着正则表达式引擎将会期望该字符出现**零次或一次**。
使用正则来匹配 favorite和favourite这两种写法。
favou?rite
使用正则来匹配codejiaonang的不同写法

code.?jiaonang
匹配多个数据
重复
在一个字符组后加上{N} 就可以表示在它之前的字符组出现N次

编写正则匹配所有的电话号码。

\d{3}-\d{5}
重复区间
可能有时候,我们不知道具体要匹配字符组要重复的次数,比如身份证有15位也有18位的。
这里重复区间就可以出场了,语法:{M,N},M是下界而N是上界。

\d{3,4} 既可以匹配3个数字也可以匹配4个数字,不过当有4个数字的时候,优先匹配的是4个数字,这是因为正则表达式默认是贪婪模式,即尽可能的匹配更多字符,而要使用非贪婪模式,我们要在表达式后面加上 ?号。
使用正则表达式提取电话号码,假设电话号码有两种规则:
- 以3个数字开头,后面
7个数字,例如:020-7281333 - 以4个数字开头,后面
7个数字,例如:0731-8283431
\d{3,4}-\d{7}
开闭区间

闭区间不写即可表示匹配一个或无数个。
可以使用两个速写字符指定常见的重复情况,可以使用 + 匹配1个到无数个,使用 *代表0个到无数个


正则表达式匹配以f开头的数据。

f\w+
使用正则表达式匹配手机号码,假设手机号码规则如下:
- 必须是
11位的数字; - 第一位数字必须以
1开头,第二位数字可以是[3,4,5,7,8]中的任意一个,后面9个数是[0-9]中的任意一个数字。
1[34578][0-9]{9}
匹配以 http开头,以/结尾的所有数据

http.*/$
小结
| 实例 | 描述 |
|---|---|
[Pp]ython |
匹配 “Python” 或 “python”。 |
rub[ye] |
匹配 “ruby” 或 “rube”。 |
[abcdef] |
匹配中括号内的任意一个字母。 |
[0-9] |
匹配任何数字。类似于 [0123456789]。 |
[a-z] |
匹配任何小写字母。 |
[A-Z] |
匹配任何大写字母。 |
[a-zA-Z0-9] |
匹配任何字母及数字。 |
[^au] |
除了au字母以外的所有字符。 |
[^0-9] |
匹配除了数字外的字符。 |
| 实例 | 描述 |
|---|---|
. |
匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。 |
? |
匹配一个字符零次或一次,另一个作用是非贪婪模式 |
+ |
匹配1次或多次 |
* |
匹配0次或多次 |
\b |
匹配一个长度为0的子串 |
\d |
匹配一个数字字符。等价于 [0-9]。 |
\D |
匹配一个非数字字符。等价于 [^0-9]。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
\w |
匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。 |
\W |
匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]‘。 |
分组
在正则表达式中还提供了一种将表达式分组的机制,当使用分组时,除了获得整个匹配。还能够在匹配中选择每一个分组。
要实现分组很简单,使用()即可。


<div>(.*?)</div>

(\d{4})[\- ]?(\d{4})[\- ]?(\d{2})
或者条件
使用分组的同时还可以使用 或者(or)条件。
例如要提取所有图片文件的后缀名,可以在各个后缀名之间加上一个 |符号:

提取所有视频文件
视频文件的后缀名有 .mp4、.avi、.wmv、.rmvb
请编写正则表达式提取所有的视频文件的后缀

.*(.mp4|.avi|.wmv|.rmvb)
非捕获分组
有时候,我们并不需要捕获某个分组的内容,但是又想使用分组的特性。
这个时候就可以使用非捕获组(?:表达式),从而不捕获数据,还能使用分组的功能。
例如想要匹配两个字母组成的单词或者四个字母组成的单词就可以使用非捕获分组:


(75855)
匹配标签

(?!<p>|</p>)<.*